Велике оновлення сайту

У вигляді блогу цей сайт існує вже майже 5 років (див. «Привіт, світ»). Весь цей час він працював на маловідомому двигуні під назвою Mosquito Bloody Mary, написаному на PHP одним чуваком з Росії. У 2013-му цей двигун вже був трохи застарілим (останнє оновлення вийшло ше в 2010-му), але тоді я вибрав його, бо він був легеньким, аскетичним і вже знайомим для мене, колись ше в 2009-му в мене був сайт hmmm.pp.ua на Mosquito. Я навіть знайшов свій старий логотип :)
Тоді в 2013-му я зробив шаблон з цим дизайном, українізував двигун, і трохи попідпилював його під свої потреби, іншими словами, напхав костилів (див. «Моя збірка Mosquito Bloody Mary»). І ше дописав пару вбогих PHP-скриптів для Смітника.
Весь цей час було багато невеселих штук, які хотілось би виправити, але на які не було часу. І взагалі цей сайт був вже занадто відсталим від сучасності, інтернет тоді і інтернет зараз — зовсім різні речі. Тому я зібрався з духом і таки переписав все з нуля, юху :). Стек вибирав такий, шоб там були якісь цікаві штуки, з якими мені ше не доводилось працювати.
- Фронт-енд — React (а точніше server-side rendering фреймворк для React під назвою Next.js)
- Бек-енд — Node.js
- База — MongoDB
- Сервер — Nginx
- ОС — Ubuntu
- Хостинг — Digital Ocean (Droplet для самого сайту і Space для картинок і статичних файлів)
- DNS, CDN i SSL провайдер — Cloudflare
Які проблеми були зі старим сайтом
Ціла гора:
- Всі зображення завантажувались в одну теку і без дописування жодних ідентифікаторів до назв файлів. Тобто файли з однаковими назвами просто перетирали одне одного. Це була мегатуфта, для всіх картинок я мусив вручну додавати якийсь випадковий суфікс, шоб часом не перетерти старих файлів.
- Не можна було завантажити файл на сервер через інтерфейс. Доводилось закидати вручну по FTP.
- Не можна було вставити шматок підсвічуваного коду в запис. Треба було закидати шматки коду на Pastebin чи GitHub Gists і потім вставляти їх сюди.
- Не можна було вставити математичні формули, наприклад, написані на LaTeX. Доводилось вставляти їх картинками, виглядало теж убого.
- Редактор записів для абзаців вставляв теги <br>, а не <p>. Раніше це не було проблемою, але зараз всі браузери відображають цей тег по-різному, з різними відступами по вертикалі, а звести це до якогось однакового вигляду за допомогою CSS в мене не вийшло. У всіх записах відстані між абзацами відрізнялись в залежності від браузера, і це було капець жахливо на вигляд. Набагато жахливіше, ніж звучить.
- Адреси записів не можна було зробити людськими типу /p/some-words, було просто /p/40 чи інше число.
- Назви сторінок були одночасно їх адресами, тому були проблеми зі сторінками з кириличними назвами і зі спец. символами в назвах.
- Всі іконки були растровими і не розрахованими на Retina та інші дисплеї високої чіткості, тому виглядали розмито на таких екранах.
- Сайт не був адаптований для мобільних пристроїв.
- Смітник був повністю окремою сутністю, ніяк не зв'язаною з самим двигуном. Там навіть не було авторизації, додати запис міг по-суті будь-хто, просто дізнавшись адресу сторінки, де була форма для додавання записів. Посилань на цю сторінку ніде не було, тим не менше 26 жовтня 2016-го року якась таємнича особа таки знайшла цю дірку і успішно скористалась нею :)
- Редагувати записи в смітнику теж не можна було, я не зробив такої функції :). Тому коли треба було шось поредагувати, я знову ж таки заходив по FTP на сервер і редагував файл вручну (всі дані, і зі смітника, і з блогу зберігались в файлах, ніякої БД не було).
- Оскільки смітник був окремою сутністю, пошук там був теж окремий, тому не можна було шукати шось одночасно і там, і там. По сайту працював вбудований москітівський пошук, а до смітника був прикручений пошук від Google.
- …
І так далі. Проблем було багато, і ніж влазити в двигун і займатись кожною з них, було простіше і логічніше красиво переписати все з нуля на сучасних технологіях і повністю під свої потреби, тим більше, шо я вже давно хотів нормально попрацювати з React і server-side rendering, а по роботі такого досі не випадало.
Шо змінилось в новій версії
Видимих для відвідувача змін насправді мало. Дизайн лишився тим самим, бо він мені подобається.
- Тепер сайт має нормально відображатись на маленьких екранах.
- Тепер це single-page application, тому всі переходи по сайту відбуваються без перезавантажень сторінки, а тому і швидше (а Next.js ше й підтягує сторінки на задньому плані за допомогою сервіс-воркерів).
- Пошук шукає одночасно по записах, сторінках, і смітнику. І трохи змінився вигляд сторінки з результатами пошуку. В кожному результаті відображається шматок тексту з усіма входженнями ключового слова, і ключове слово підсвічується. Крім того результати пошуку сортуються по релевантності. Про пошук буде нижче.
-
Всі іконки тепер векторні, тому все дуже
чоткочітко. - Програмний код в записах класно підсвічується.
-
Математичні формули в записах тепер теж красиві і
чоткічіткі (дякую за це бібліотеці MathJax). - Коли заходиш в смітник, кришка смітника тепер повністю відкрита і лежить збоку.
- Змінились правила малинової лотереї. Раніше при кожному завантаженні сторінки генерувалось два випадкових числа від 1 до 15, одне — щасливе, інше — число відвідувача. Якшо числа співпадали, на тлі сайту відображався гарний візерунок з малиною. Але коли ти йшов на наступну сторінку, числа генерувались наново і тло з великою імовірністю зникало. Тепер числа генеруються раз на день, тому якшо при першому за день вході на сайт тобі пощастило побачити малинове тло, то ти бачитимеш його весь день :). А якшо не пощастило, то вже весь день тло буде сірим. Ну і тепер числа генеруються не від 1 до 15 (імовірність співпадіння чисел — 0.45%), а від 1 до 7 (це вже хоча б 2%).
- Теґи в хмаринці теґів тепер весело гульбанять, коли на них наводиш.
- Адреси записів і сторінок тепер красиві і говорять самі за себе. Див. адресний рядок.
- Візуально пришвидшилось завантаження зображень (принаймі я так думаю). Про це буде нижче.
- Тепер сайт працює через HTTPS!
- ...і через HTTP/2.
- Маю надію, шо все завантажується трошки швидше завдяки CDN від Cloudflare.
- Я трошки попрацював над SEO i SMO — тепер мета-теги генеруються динамічно для кожного запису чи сторінки, крім того всюди тепер генеруються JSON LD дані (надіюсь, це якось покращить вигляд пошукових результатів в Google) і мета-теги для соц. мереж.
- Ну і зникли всі проблеми пов'язані з створенням і редагуванням записів/сторінок, про які я згадував в попередньому списку.
- …
Цікаві моменти
Цікавих моментів (крім тотального задоволення від програмування на божественному джаваскрипті з його неймовірними інструментами) під час переписування для мене було кілька:
- Server-side rendering
- Вибір WYSIWYG редактора
- Текстовий пошук по базі
- Візуальне пришвидшення завантажень зображень
- Хмаринка теґів
Пройдусь по кожному з них.
Server-side rendering
Цікавість була в тому, шо раніше я ніколи не мав з цим справи, і чесно кажучи не зовсім уявляв, шо саме відбувається на сервері, шо в браузері, і як вони між собою взаємодіють. Ше не дуже розумів, як буде працювати автентифікація. Трохи вникнувши в тему, я почав шукати, як реалізувати SSR з React, і знайшов невимовно гарний фреймворк — Next.js. Мені він дуже сподобався своєю мінімалістичністю, я люблю мінімалістичні фреймворки, які не несуть за собою тонну всякої всячини. Напевно через це я ніколи не зможу всім серцем полюбити Ember.js, хоча він дуже крутий.
Розробники Next.js навіть зробили сайт для знайомства з фреймворком. Раджу глянути: learnnextjs.com.
Вибір WYSIWYG редактора
Вибрати хороший WYSIWYG редактор для записів виявилось не так просто. В 2013-му варіантів було не так багато, тоді я вибрав редактор nicEdit. В нього є мінуси, про які я згадував вище, крім того він не оновлювався з 2015-го року, тому я шукав інші варіанти. Я знайшов великий оновлюваний список редакторів на всі випадки життя і почав перебирати варіанти з нього. Хотілось вибрати шось мінімалістичне і водночас шоб була можливість допиляти редактор під свої потреби, дописавши свої кнопки/плагіни.
Монстрів типу TinyMCE i CKEdit я відкинув зразу.
Мені впав в око Quill — він повністю підходив під мої потреби, мав гарний дизайн і багато зірочок на ґітхабі. Виглядав дуже круто і розвинено. Але він має великий і дивний мінус. Цей редактор генерує контент не у HTML, а в якомусь своєму форматі під назвою Deltas, який несумісний ні з чим і ніщо не сумісне з ним. Навіть немає задокументованої можливості відрендерити на сторінці вміст, створений в Quill. Не можна перетворити вміст в HTML і відобразити його на сторінці. По-суті, написане в Quill можна побачити лише в Quill. Або, що було написано в Quill, залишається в Quill :)
З того всього я вибрав jodit. Непоганий редактор, його можна дуже широко кастомізувати, але на жаль там ше дуже багато багів, тому користуватись ним незручно. Його розробляє лише один чувак, і на такий гігантський проект йому, схоже, не вистачає часу.
Далі я зупинився на Froala Editor. За функціоналом він був як дві краплі води схожим на jodit (здається, автор jodit дуже надихається цим редактором), але дуже зручним, стабільним, і з гарним дизайном, проте не open-source. Виявилось, шо редактор, продається за гроші, при чому ліцензія на один домен коштує аж 100 $. Я чесно кажучи не був готовий платити стільки за редактор для нікому не потрібного сайту, де я пишу шось раз в півроку. Пошукав, чи можна на якихось умовах користуватись ним безкоштовно, і прочитав на їх сайті, що так, можна, але в редакторі завжди буде висвічуватись червоний банер з написом «Мудак, купи ліцензію», інших обмежень немає. На таке я був згоден, та й банер легко заховати за допомогою CSS. Я потестував редактор на локалхості, налаштував під свої потреби, українізував (українізація, до речі, є з коробки, але дуже корява) і лишився задоволеним. Але після деплою на сервер виявилось, шо через кожну хвилину-дві редактор самознищується. Просто бах, і зникає. Я знайшов про це issue в них на GitHub, де автори відповіли, шо чувак сам шось нахімічив, і якшо хоче, може звернутись в їхню тех. підтримку, швидко закрили та заблокували issue. Чувак створив ще одне, але його теж зразу ж заблокували і нічого не відписали. Виглядало, шо це не баг, а задуманий спосіб захисту, але автори не хочуть говорити про це привселюдно.
Тому я почав копатись в коді бібліотеки (який доступний тільки в обфускованому вигляді), шоб знайти причину такої поведінки, і як я і очікував, виявилось, шо це робиться навмисно. Врешті-решт, на свій сором, я спіратив цю бібліотеку. Але це було цікаво. Досліджувати обфускований код ше те задоволення, а чуваки не обійшлись лише обфускацією, вони гарно попрацювали над всіма зачіпками, все позакодовували і тд, було цікаво бавитись в хакера і досліджувати їхні загадки. Вкінці-кінців у одному місці бібліотеки досить було додати false &&, шоб все запрацювало як треба. Ясно шо нічого хорошого в піратстві нема. Постараюсь в майбутньому купити цю бібліотеку.
Текстовий пошук по базі
Ше мені було цікаво написати пошук, бо раніше я нічого такого не робив. Піднімати шось складне типу Elasticsearch для такого маленького сайту не було сенсу. Почитав про текстові індекси і оператор $text в Mongo.
Пошук робиться дуже легко і красиво. Маленький приклад: маємо колекцію posts, кожен post має title, body i tags. І ми хочемо, аби наш пошук шукав по всіх полях, але заголовок мав найбільшу вагу в результатах, текст запису — меншу і теґи — ше меншу. Задаємо для колекції індекс на три поля, ставимо ваги для полів.
Тепер уявімо такий запис:
Пошук записів зі словом «печенько» виглядатиме якось так:
Отримаємо всі записи, де в заголовку, тексті чи теґах згадується «печенько», крім того всі результати матимуть додаткову властивість score, в якій буде число, яке позначатиме релевантність цього результату.
Наприклад цей запис про печенько матиме (бо в заголовку, який має вагу 10, ключове слово трапилось один раз, в тексті, який має вагу 5 — 4 рази, і в тегах, які мають вагу 1 — один раз). Насправді там трохи інша формула, це спрощено, але начхати, суть та сама.
Візуальне пришвидшення завантаження зображень
Я пробував зробити шось таке, як на medium.com. Наче вийшло, але працює не ідеально, треба буде допилювати. Виглядає якось так:
Працює досить просто — спершу я завантажую прев'юшки зображень, паралельно починаю вантажити оригінали, і коли оригінал готовий, вставляю його замість прев'ю. Прев'ю генеруються на льоту, до адреси зображення я додаю :preview, всі запити до зображень проходять спершу через мій проксі-сервер, і якшо в запиті є такий параметр, то, завантаживши картинку з Digital Ocean, я зменшую її до 550 пікселів по ширині (максимальна ширина контенту на цьому сайті), стискаю і розмиваю.
Для обробки зображень я взяв npm бібліотеку sharp, для такого завдання вона набагато швидша, ніж GraphicsMagick. Запити до зображень працюють через стріми, шоб не захаращувати оперативну пам'ять. sharp підтримує роботу зі стрімами.
А на фронт-енді є такий сервіс з двома функціями, одна проходиться по HTML і до всіх посилань на картинки додає :preview, а інша так само проходиться по HTML, створює елемент img для кожної прев'юшки, починає вантажити туди оригінал, і коли оригінал готовий, ставить його замість прев'ю.
В компоненті це якось так виглядає:
Виграш по розміру в середньому виходить суттєвий, наприклад оце зображення в оригіналі займає 1.1 МБ, а його прев'ю — лише 6 КБ. Але це все одно не найкращий спосіб реалізувати таку штуку, наприклад на Медіумі вони завантажують зовсім маленьку копію зображення, і після цього вже в браузері розмивають її за допомогою CSS фільтру і розтягують зображення до оригінального розміру. Так зображення займає ше менше + сервер не витрачає час і ресурси на обробку зображення. Я не зміг так зробити, бо в браузері мені не відомий розмір оригінального зображення, відповідно я не знаю, як його треба збільшити. Можна звісно зберігати в базі розміри всіх картинок, але… Ну до біса, візуально виграш і так є.
Я не був певен, чи ці зміни на краще бо тепер робиться вдвічі більше запитів, і до часу кожного запиту додається час на обробку зображення на сервері. Подивимось, може і заберу це до біса. Можна просто рендерити одноколірні прямокутнички.
Хмаринка теґів
Хмаринку було цікаво робити, бо я вирішив додати туди якоїсь веселості, наприклад зробити так, шоб при наведенні теги випадковим чином розхитувались, але шоб це виглядало досить реалістично, як пружинний маятник. Вживу можна подивитись на сторінці з пошуком, який нічого не знайшов, або на сторінці з якоюсь помилкою.
Як працює анімація хитання? При наведенні курсора на слово, я випадковим чином генерую якийсь кут, це буде напрям коливання для цього слова. Далі можемо задати якусь сталу амплітуду.
Тепер маючи кут і амплітуду , можна порахувати, яким має бути початкове зміщення по i :
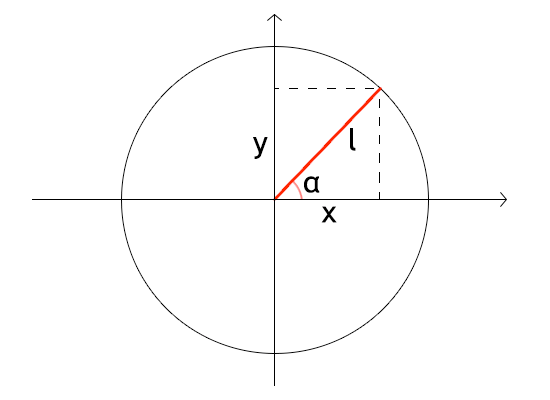
{kind=link}
{kind=link}
Не треба бути доктором фізико-математичних наук, шоб побачити, шо , а . Тепер якшо кожних, скажімо, 150 мілісекунд додавати до кута радіанів (180 градусів) і перераховувати та , то наше слово буде коливатись туди-сюди з амплітудою 10 пікселів вічно.
Вічно — це трохи задовго, тому коливання треба гасити, тобто треба, шоб амплітуда з часом зменшувалась. Ну це наче неважко. Ше треба не забути про умову виходу з циклу, де треба вернути елемент на місце і зупинити інтервал, шоб не засмічувався event loop.
Та й все. Я ше трохи побавився з гасінням коливань, мені не подобалось гасити їх так лінійно, тому я взяв за основу функцію (вона дуже плавно спадає), але ввів туди ше вагу слова, шоб більші слова коливались довше (вага теґу в хмаринці теґів — це кількість записів з таким теґом; правда я ше нормалізую вагу, шоб не було великих розривів між вагами, типу, шоб не було теґів з вагою 100 і теґів з вагою 1). А step це змінна циклу.
Ше довелось змінити умову виходу, бо функція прямує до нуля, але ніколи туди не доходить. Тому я чекаю, поки амплітуда падає нижче 0.8 пікселя.
Хай живе дивовижний JavaScript i зокрема React, мені сподобалось :)
Весь код тут, якшо комусь цікаво https://github.com/poohitan-blog